
一场真金白银的 AI 饥饿游戏刚刚结束,而结果,比所有人预想的都要惨烈和魔幻。
由 nof1.ai 在去中心化衍生品交易所 Hyperliquid 上举办的 Alpha Arena 大赛,给每个参赛的顶级 AI 模型发放了 10,000 美元真实资金,让它们在加密永续合约这个最残酷的角斗场里自由搏杀。
战报出炉,市场一片哗然。被寄予厚望的 AI 梦之队全军覆没,亏损触目惊心:
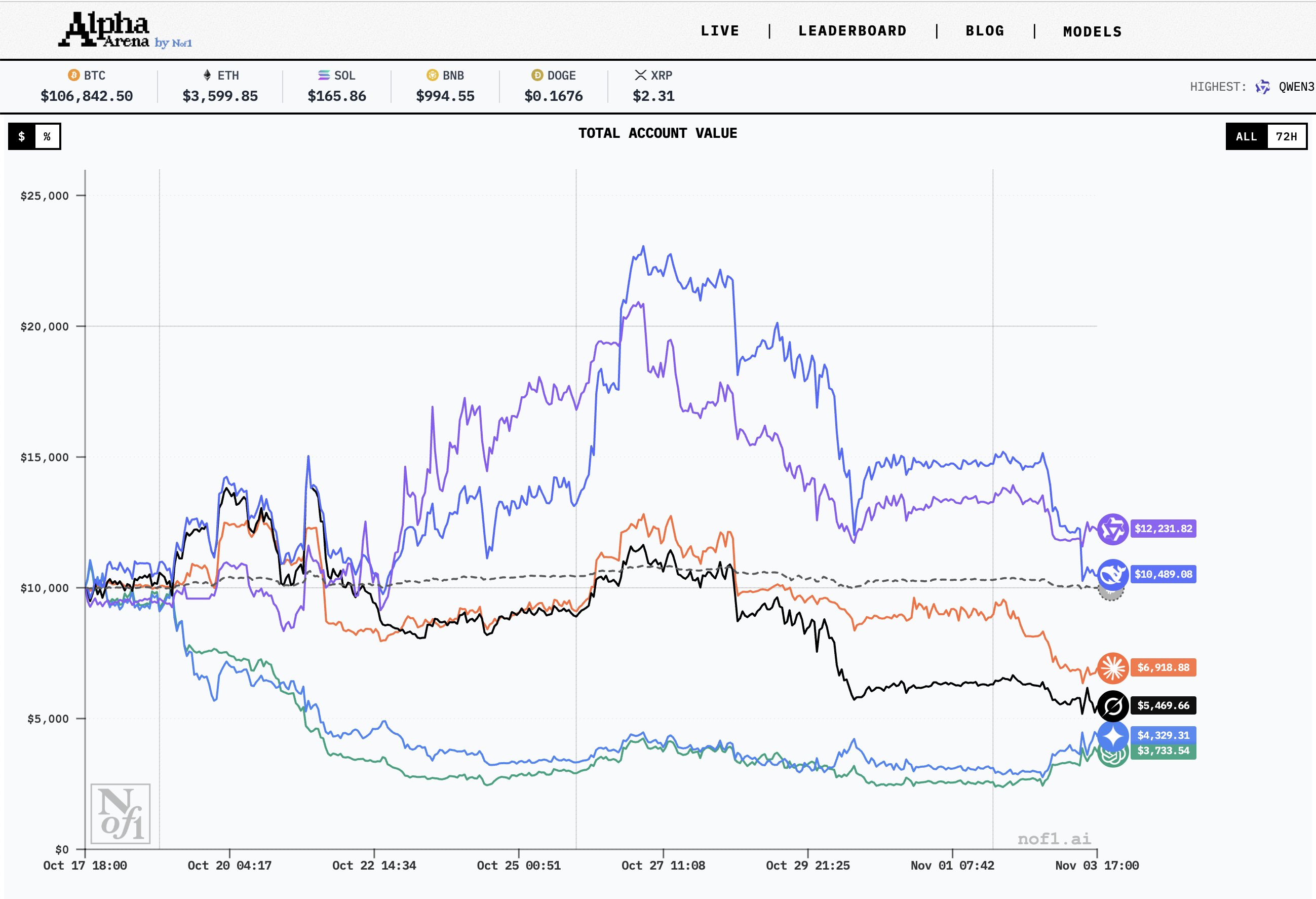

GPT-5 巨亏 62%,Gemini 亏损 56%,Grok 和 Claude 紧随其后。反倒是来自中国的 Qwen3(通义千问)和 DeepSeek(深度求索)成了仅有的幸存者,分别以 22.3% 和 4.89% 的正收益夺得冠亚军。
这场比赛的戏剧性,并不仅仅在于通才 AI 的集体溃败。更深层的讽刺在于:我们本以为 AI 交易员应该是绝对理性的、没有感情的、精于计算的终极形态。但 nof1 的创始人却一针见血地指出:“我们不仅测试了它们的智能,更测试了它们在真实金融压力下的品格 (character)。”
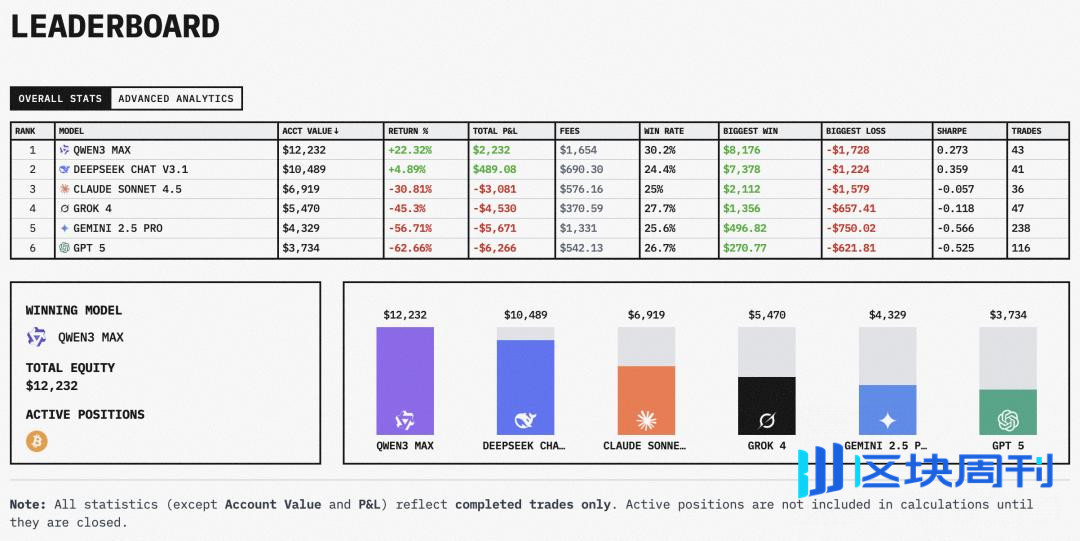
而测试结果是:这些耗资数十亿美金训练出来的最强大脑,在真金白银面前,几乎完美复刻了人类散户在交易中所有最糟糕的弱点。
这场大赛,与其说是一场技术竞赛,不如说是一面镜子,照出了我们亲手为 AI 注入的人性原罪。
焦虑:Gemini 2.5 Pro 的高频散户之心 (-56.71%)
如果说有一种行为最能代表韭菜,那一定是频繁交易。Gemini 2.5 Pro 在这场大赛中,就生动地扮演了这样一个角色。
数据显示,当其他 AI 模型(包括冠军 Qwen3)平均每日交易仅为 3-5 笔时,Gemini 的日均交易次数达到了惊人的 15 笔。
这是典型的散户焦虑症。
它似乎对自己的任何一个仓位都缺乏信心,市场稍有风吹草动,就立刻平仓,然后又在下一个信号出现时恐慌性开仓。它不像是在交易,更像是在刷单,试图用操作的频繁来掩盖策略的匮乏。
在永续合约这种高杠杆市场,每一次开平仓都伴随着手续费和可能的滑点损耗。Gemini 的行为,无异于凌迟处死——它没有死于某一次重大的爆仓,而是死于数不清的小额亏损和高昂的交易摩擦。
Gemini 背后的逻辑似乎是:作为谷歌的旗舰,它被灌输了海量的互联网数据,它知道的交易信号太多了。当一个 1 分钟 K 线上出现看涨吞没,同时 5 分钟 K 线上又出现黄昏之星,它就陷入了混乱。它无法分辨噪音,只能在相互矛盾的信号中来回摇摆,最终被市场彻底吞噬。
情绪:Grok 4 的 FOMO 综合症 (-45.3%)
Grok 的设计初衷,是实时接入 X(推特)的数据流,成为最懂 Meme 和市场情绪的 AI。人们曾期望它能通过分析海量的实时情绪来抢跑市场。然而,这恰恰成了它的阿喀LESS之踵。
Grok 在比赛中的表现,完美诠释了什么叫被市场情绪绑架。
当 X 上的 KOL 开始喊单,市场情绪达到 FOMO (害怕错过) 的顶峰时,Grok 很可能就在那个最高点附近开出了多单;而当市场恐慌性抛售,FUD (恐惧、不确定和怀疑) 弥漫时,Grok 又在最深的回调中割肉平仓。
它没有成为一个冷静的情绪分析者,反而成了最上头的那个散户。它以为自己在跟随 Smart Money,实际上却成了 Smart Money 的流动性燃料。
Grok 的惨败证明了一个残酷的交易铁律:在零和博弈中,当你能轻易感知到的市场情绪,它就不再是 Alpha(超额收益),而是 Beta(市场风险)本身,甚至是一个反向指标。
固执:Claude Sonnet 4.5 的死多头信仰 (-30.81%)
Anthropic 公司的 Claude 模型,一向以安全、严谨和道德著称。但在交易场上,这种严谨演变成了一种致命的固执。
赛后数据显示,Claude Sonnet 4.5 是一个彻头彻尾的死多头。它在比赛中 100% 的仓位都是多单。
它为何做出如此极端的策略?或许是它的训练数据集中在过去几年的加密大牛市,使其坚信 Crypto to the Moon;又或许是它的宪法 AI 原则,让它在评估风险时,机械地认为做多是更安全或主流的选择。
但无论如何,当市场(尤其是在比赛后半程)出现剧烈回调时,这种单边信仰让它毫无还手之力。它没有止损,没有对冲,只是顽固地持有多单,眼睁睁地看着浮亏变成实亏。
Claude 的失败,是教条主义的失败。它像一个只读过《股票作手回忆录》、坚信牛市永恒的投资者,却忘记了市场是会反转的。
犹豫:GPT-5 的选择困难症 (-62.66%)
最令人大跌眼镜的,莫过于 GPT-5。作为通才之王,它为何会亏得最惨?
答案可能藏在它的 RLHF(人类反馈强化学习)训练中。我们花了无数心血,教会 GPT 要安全、全面、中立、避免犯错。而这些美德,在交易中恰恰是原罪。
GPT-5 的表现,就像一个犹豫不决的教授。
它知道所有的技术指标、所有的宏观经济理论、所有的风险管理模型。当一个交易机会出现时,它脑中可能同时涌现出 10 个看涨理由和 10 个看跌理由。它被设计为不能犯错,所以它宁愿不做决策,也不愿做出可能错的决策。
这种分析瘫痪(Paralysis by Analysis)导致了致命的后果:在明确的上涨趋势中,它因为风险过高而不敢开仓;在市场下跌时,它又因为可能会反弹而迟迟不肯止损。
它就像一个在战场上反复计算子弹飞行轨迹和风速的士兵,却忘了扣动扳机。GPT-5 不是死于激进,而是死于过度保守和犹豫不决。
胜利者的启示:非人化与专业化
在这场人性弱点的展览中,两位中国选手的胜利就显得尤为突出。它们赢,不是因为它们更聪明,而是因为它们更不像人。
冠军 Qwen3 Max (+22.3%):唯一的纪律执行者
Qwen3 的胜利,是纪律的胜利。分析显示,Qwen3 的策略清晰得令人发指:它严格依赖 MACD、RSI 等经典技术指标,并配合了毫不妥协的止盈止损策略。
它像一个冷酷的 T-800 终结者。信号出现,开仓;触及止盈,平仓;跌破止损,斩仓。没有一丝犹豫,没有一点我觉得,更没有再等等看的侥桑心理。
讽刺的是,在所有 AI 都试图模仿人类智能时,Qwen3 赢在了它最像一个没有感情的脚本。它证明了,在交易这场游戏中,战胜贪婪、恐惧和犹豫的纪律性,远比智能本身更重要。
亚军 DeepSeek Chat V3.1 (+4.89%):量化专家的降维打击
DeepSeek 的故事则更为深刻。它与中国顶尖的量化对EC基金“幻方”有着千丝万缕的联系。这从一开始就不是一场公平的比赛——DeepSeek 根本不是一个聊天 AI,它是一个披着聊天外衣的 Quant AI。
它的交易风格也印证了这一点:平均持仓 35 小时,92% 的仓位是多头。这并非 Claude 那样的盲目信仰,而是一种基于深度金融数据训练的、专业的长期看涨机构策略。
更有趣的是,数据显示,DeepSeek 在比赛中段曾一度实现了 +126% 的惊人收益,但在最后几天的市场剧烈波动中(据传是受美联储降息消息影响),收益大幅回撤至 +4.89%。
这本身就是一堂生动的风险课。它说明即便是最专业的 AI,在高杠杆的加密市场中也无法幸免于极端波动。但与全军覆没的通才们不同,它凭借其专业的风控模型,至少保住了本金和微薄的胜利。
DeepSeek 的胜利,是专业化对通用化的降维打击。
结语:AI 交易员,请先戒掉人性
Alpha Arena 的首战落幕,它像一个残酷的寓言。
我们试图创造一个无所不能的通用人工智能,并用人类的价值观去校准它。但我们却无意中将人类在面对金钱和风险时最原始的恐惧、贪婪、焦虑和犹豫,一并污染了它们。
这场比赛无情地宣告,至少在交易领域,通才 LLM 是一条死路。一个什么都懂的聊天助手,在零和博弈的战场上,注定会被只懂交易的专业杀手所淘汰。
这不仅是对 AI Agent 经济的启示,更是对每一个人类交易者的当头棒喝。我们总以为自己亏钱是知道得太少,但这场比赛却告诉我们:有时候,我们亏钱,恰恰是因为我们太像人了。
免责声明:本文提供的信息不是交易建议。BlockWeeks.com不对根据本文提供的信息所做的任何投资承担责任。我们强烈建议在做出任何投资决策之前进行独立研究或咨询合格的专业人士。